







 DeepSeek超越ChatGPT登顶美区App Store免费榜,R1新模型深耕“强化学习”比肩OpenAI o1查询成本更低丨科股一线拆解
DeepSeek超越ChatGPT登顶美区App Store免费榜,R1新模型深耕“强化学习”比肩OpenAI o1查询成本更低丨科股一线拆解导读:
- DeepSeek正式发布DeepSeek-R1,并同步开源模型权重,其在AIME2024数学基准测试中成功率达到79.8%,略高于OpenAI-o1-1217;在MATH-500基准测试中,以97.3%的成绩超越o1的96.4%。
- 截至目前,DeepSeek在苹果App Store应用商店美区免费榜的排行已跃升至首位,超越ChatGPT、Google Gemini、Microsoft Copilot等美国生成式AI产品;在新加坡、英区免费榜排行也分别排行第一和第二。此外,苹果App Store中国区免费榜显示,DeepSeek还成为中国区第一。
- DeepSeek-R1高性价比的API定价,极具商业化落地潜力。其定价为每百万输入tokens 1元(缓存命中)/4 元(缓存未命中),每百万输出tokens 16元,远低于可比大模型API服务。
- 2024年12月26日,深度求索正式上线全新系列模型DeepSeek-V3首个版本并同步开源,其在英语、代码、数学、汉语以及多语言任务上,不仅超越阿里云Qwen2.5-72B、Meta的Llama-3.1-405B等开源模型,且在性能上逼近GPT-4o、Claude-3.5-Sonnet等世界顶尖闭源模型,大大缩小了开源和闭源AI之间的差距。
- AI科技初创公司Scale AI创始人亚历山大·王公开表示,过去十年来,美国可能一直在人工智能竞赛中领先于中国,但DeepSeek的AI大模型发布可能会“改变一切”。
正文:
在开源大模型领域,幻方量化深度求索再落一子,东方力量悄然崛起。近日,DeepSeek正式发布一系列DeepSeek-R1模型,包括DeepSeek-R1-Zero、DeepSeek-R1和DeepSeek-R1-Distill系列。其中,DeepSeek-R1模型推理能力优异,比肩OpenAI o1正式版。
截至目前,DeepSeek在苹果App Store应用商店美区免费榜的排行已跃升至首位,超越ChatGPT、Google Gemini、Microsoft Copilot等美国生成式AI产品;在新加坡、英区免费榜排行也分别排行第一和第二。此外,苹果App Store中国区免费榜显示,DeepSeek还成为中国区第一。
DeepSeek-R1在后训练阶段大规模使用了强化学习技术,在仅有极少标注数据的情况下,极大提升了模型推理能力。从性能来看,该模型在标准化编码测试中表现出“专家级”性能,在Codeforces上获得2029Elo评级,超越了96.3%的人类竞争对手。
而在AIME2024数学基准测试中,其成功率达到79.8%,略高于OpenAI-o1-1217;在MATH-500基准测试中,DeepSeek-R1以97.3%的成绩超越o1的96.4%;在MMLU(大规模多任务语言理解)测试中达到90.8%的准确率,虽略低于o1的91.8%,但显著优于其他开源模型。
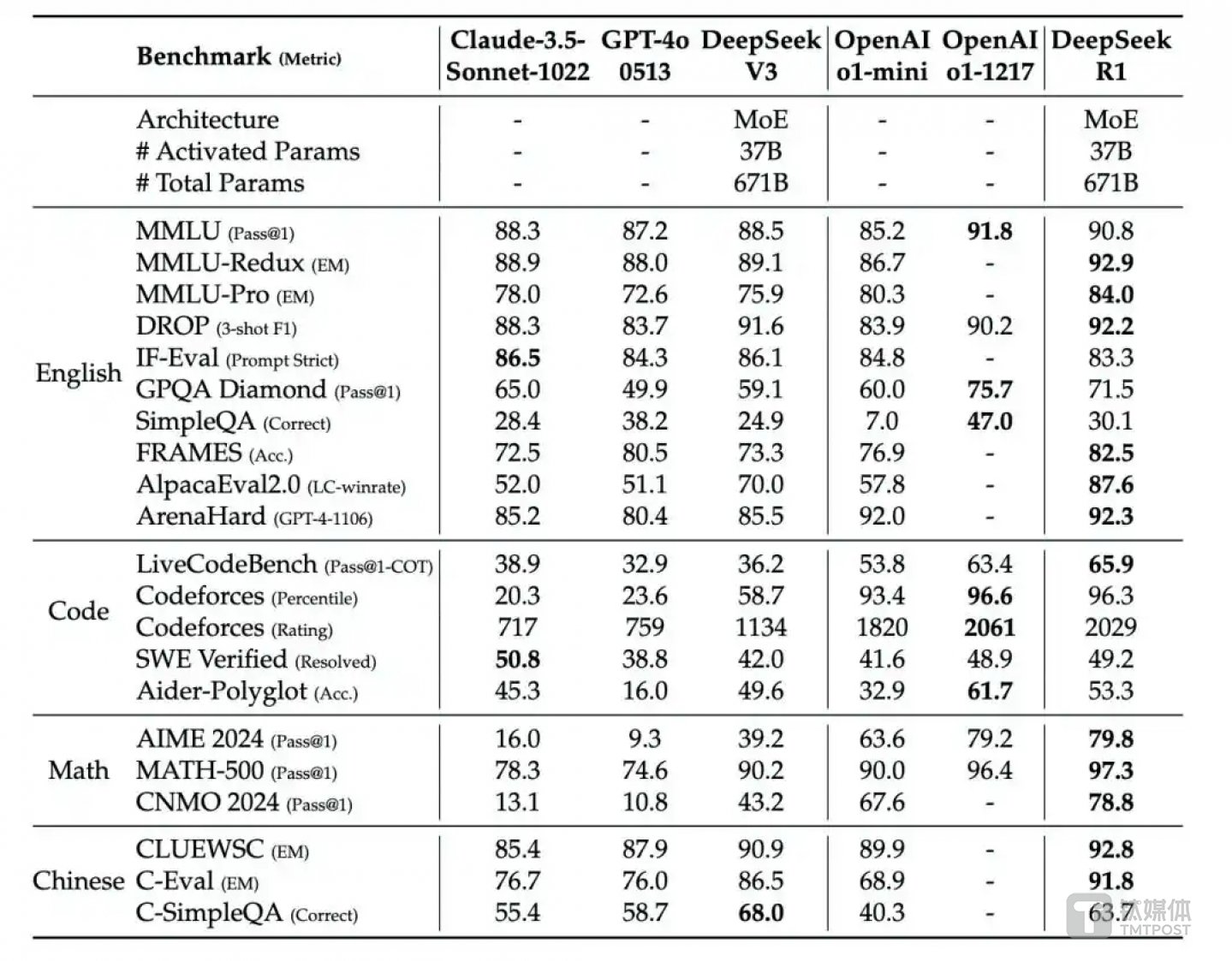
DeepSeek-R1与其他代表性模型比较,来源:DeepSeek
DeepSeek-R1高性价比的API定价,极具商业化落地潜力。其定价为每百万输入tokens 1元(缓存命中)/4 元(缓存未命中),每百万输出tokens 16元,远低于可比大模型API服务。
且与专有模型不同,DeepSeek R1的代码和训练方法在MIT许可下完全开源,这意味着任何人都可以获取、使用和修改该模型而不受限制,也有助于开发者在使用后,加速模型的功能迭代,从而解决目前模型存在的不足。
近一个月来,DeepSeek在开源大模型领域的探索不可谓不吸睛。在2025年达沃斯论坛上,AI科技初创公司Scale AI创始人亚历山大·王公开表示,过去十年来,美国可能一直在人工智能竞赛中领先于中国,但DeepSeek的AI大模型发布可能会“改变一切”。
2024年12月26日,深度求索正式上线全新系列模型DeepSeek-V3首个版本并同步开源。经测试,在英语、代码、数学、汉语以及多语言任务上,该模型不仅超越阿里云Qwen2.5-72B、Meta的Llama-3.1-405B等开源模型,且在性能上逼近GPT-4o、Claude-3.5-Sonnet等世界顶尖闭源模型,大大缩小了开源和闭源AI之间的差距。
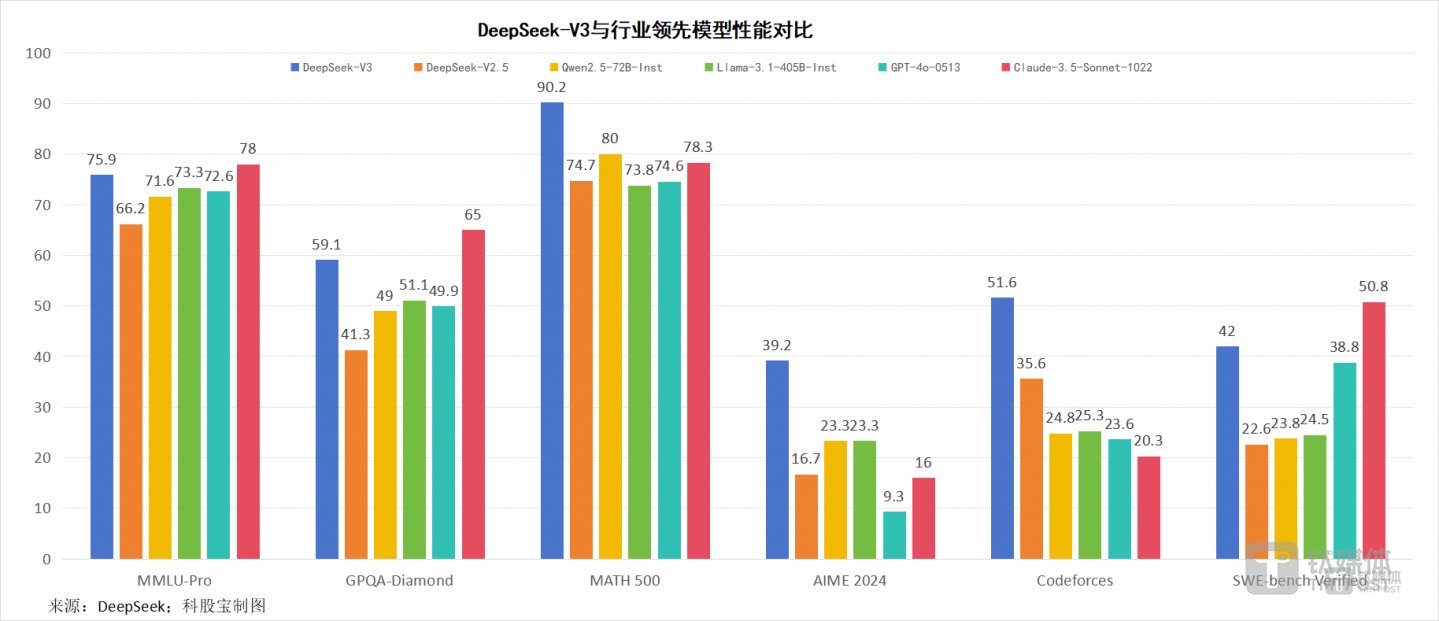
根据DeepSeek-V3技术报告,该模型整个训练使用了277.8万个GPU小时(GPU为H800),训练成本为557.6万美元。通常这种能力水平的模型需要接近16K GPU的集群,而目前一些正在部署的集群规模已接近10万块GPU。例如,Llama-3-405B耗费了3080万GPU小时,对比之下,DeepSeek-V3的算力需求减少约11倍。
其API也大幅下降,每百万输入tokens 0.5元(缓存命中)/2元(缓存未命中),每百万输出tokens 8元。DeepSeek为V3大模型提供了45天优惠价格体验期,在2025年2月8日之前,所有用户使用该模型API的价格分别下降80%(输入命中)、50%(输入未命中)、75%(输出)。技术报告显示,DeepSeek-V3成为唯一进入“最佳性价比”三角区的模型。

DeepSeek-V3位于“最佳性价比”三角区,来源:DeepSeek
长江证券认为,DeepSeek-V3说明在有限算力预算下进行模型预训练仍可以达到优秀的性能,目前在数据和算法方面仍有大量优化空间,低成本的训练和高效推理应用或将是下一阶段大模型发展的方向之一。后续有望在有限的预算下开发强劲性能的大模型,从而降低大模型的准入门槛,推动AI应用的落地进程。
2024年5月,DeepSeek率先发起国内大模型价格战,将100万token的价格降至1元人民币,迅速引发市场震动。字节跳动豆包大模型紧随其后,将价格进一步压低至100万token 0.8元人民币。阿里云通义千问则全线降价,虽然输出token降幅较小,但整体价格仍处市场低位。此外,百度、科大讯飞、腾讯等大厂也纷纷加入降价行列。
兴业证券认为,从豆包最新发布的视觉理解模型到Deepseekv3的全球关注,国内AI大模型能力被低估。伴随字节在AI领域的投入决心、豆包用户目标设定,2025年或为国内大模型真正算力军备竞赛的第一年,大厂资本开支有望持续超预期。
风险提示:产品升级不及预期;市场竞争加剧;下游应用需求不及预期;安全风险。

 最新文章
最新文章  快报
快报